Statistical Variability Worksheets
Sometimes we can come to a correct answer that we are not certain valid. What if you took a survey to find out what people’s favorite sport was? Would you get the same type of answers at a soccer field as you would at a grocery store? Sometimes we are not sure that we can make decisions based on information that we collect or are given. When we are working with statistics, we are often looking to analyze streams of data to help make sense of it. One way to analyze a data set to find out if it is valid is to determine the statistical variability of the set. This tells us how spread out the values are and, in some cases, if we can trust the figures enough to make decisions based on it. These worksheets will help you learn how to assess common measures of variability in data sets.
Aligned Standard: Grade 6 Statistics - 6.SP.A.1
- Data and Bias Step-by-step Lesson- We look at the true meaning and value of the information and if it could be corrupted or bias.
- Guided Lesson - We look into the concept of random figures, fairness, and questioning.
- Guided Lesson Explanation - These are some of most simple answers I have given thus far on the site, but they require nothing more.
- Practice Worksheet - I tried to think up every possible scenario I could fit these skills in.
- Matching Worksheet - This focuses on determining the proper questioning techniques.
- Answer Keys - These are for all the unlocked materials above.
Homework Sheets
Determining Bias within Data Collection, Random Samples and Bias In Samples.
- Homework 1 - Mary bought 5 slushies for each member in the family She did not know the preferences of flavors of each one of them. Is this sample of slushies from the shop likely to be biased?
- Homework 2 - Katie asked the class what they wanted to color today. She announced to the class that they could either color a friendly dinosaur or an evil wizard. Is this sample of the writing pages completed by the kids likely to be biased?
- Homework 3 - The nurse collected blood samples from all the patients in the hospital. Is this sample of blood likely to be biased?
Practice Worksheets
Random Samples of Data, Using Questions to Discriminate Data, and Determining Bias in Statements.
- Practice 1 - Lauren took grapes from the bag and threw it down. She picked 20 grapes which were on the table. Is this a random sample of the grapes?
- Practice 2 - When I was in market, many of the fruit shops were closed. Which of the following questions would provide you with hard data that you could use to find the reason for it?
- Practice 3 - Are the statements or questions biased? State how.
Math Skill Quizzes
Working With Statistical Variability in Data, The Bias Conditions of a Statement, and my favorite Bias in Tables and Graphs.
- Quiz 1 - Every teacher in school should know the French Language. Is this statement biased?
- Quiz 2 - Are the statements or choices biases in any way?
- Quiz 3 - Circle the word(s) in each sentence that makes the question biased.
What Is Statistical Variability in Data?
Statistical variability is also known as dispersion. It is a way to describe the trends in the way the values are spread out in a data set. It is the measure through which one data set can be compared to the others as it tells how each of the sets varies from each other. Possessing the ability to find chance difference between multiple sets of data is a valuable skill in today’s world. Just about every industry holds people who have this ability in high regard.
There are four measures of statistical variability which are used to describe the trends in your figures, which include range, interquartile range, variance, and standard deviation. These are definable qualities that you may be able to visualize on a graph or data chart. They tell us the degree of difference between all of the data points that we are looking at. This can indicate how reliable the information is and also whether an experiment or treatment worked in other fields.
Range: The difference between the largest and the smallest value in the data set is the range of the data set. To calculate the range, you simply subtract the smallest value from the largest value in the data.
Interquartile Range: Interquartile range or IQR is the difference between the half of the second half of the data set, which is three-fourth of the figures, Q3, and the half of the first half, which is one-fourth of the data set, Q1.
Variance: It tells us if the data is widely spread or tightly clustered. A small variance means the values are clustered together, and a bigger value indicates the information that was collected is widely spread.
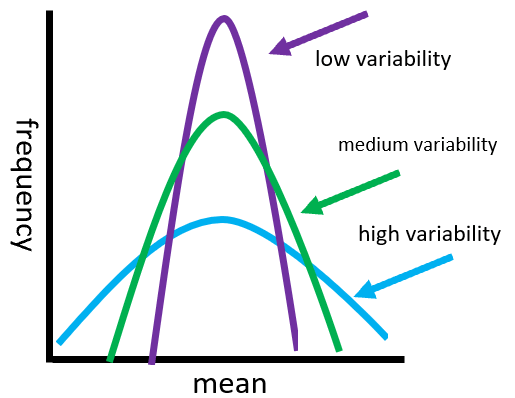
Standard Deviation: Standard deviation is the measure of how tightly clustered or widely spread the data. A larger standard deviation is an indication that your data is widely spread. When we visualize the data on a graph it really gives us a good indication of how different from the norm (mean) the data is. Take a look at the graph below. As you can see the greater distance the values are spread from the center point, the more variability and variance that exists in the data.
Why Statistical Variability Matters
Students will often begin to learn this topic but have no idea of the value of this skill in the real world. A good example that relates to you is the concept of determining if a test that a teacher gave was fair and an accurate assessment of how well a class knew the information. Think about a scenario where a class of 20 students earns a class average of 75% on a test. Most people would say that this test was too hard, based on that average. That would definitely be true if every student in the class scored 75%, but that is not how averages work. What if you were to evaluate the individual student scores and learn that 5 students got a perfect score and 4 students got 35%? This gives us a better sense of a reflection on this information.
Once we are able to detect a great deal of variance in a data set, it helps us evaluate it as a whole. If there is a great deal of variability present it makes it difficult to make confident and well-placed decision based on these data sets. In science, if the data in an experiment demonstrates a great deal of variance this often tells us that it was unreliable. Which often leads to the experiment being manipulated and retested.